AI can do amazing things today, but when it comes to the messy world of projects, things become a little more challenging

16 DEC 2022
Anyone with their pulse on the the latest technologies will have heard the buzz around ChatGPT for the last couple of weeks. But if you don’t know already, ChatGPT is an AI chatbot capable of an array of language tasks such as answering complex questions, writing essays, and even taking SAT tests and providing working software code.
ChatGPT is built on top of an improved version of the already impressive GPT3 large language model. GPT3 itself is capable of generating realistic language, answering questions and summarising text. But for me, the real breakthrough with ChatGPT is it’s ability to remember previous dialogue and keep track of themes throughout conversations. This is something that most humans can do with ease but previous large language models have struggled with up until now.
Following the launch of the multi-talented ChatGPT there has been a lot of speculation on the capabilities and limits of AI, so, is there anything AI cannot do? Yes, a lot (well at least for now!). And this especially the case when we start trying to apply AI to complex areas such as managing engineering projects.
There are 5 key areas that limit the usefulness of AI within projects:
- Poor data
- Ergodicity
- Adaptation
- Real world problems
- Adoption
Poor Data
Vast amounts of data underpin the impressive AI models of today. GPT3 was trained on about 45 TB of text data and used a massive 175 billion parameters. Meanwhile, the soon to be launched and much hyped GPT4 is said to have 100 trillion parameters! The models are getting so big that some are beginning to worry that we will run out of human generated text to train their algorithms on.
So when it comes to applying AI on projects we first have to consider the data. And the picture is not pretty. Whilst the industry is slowly moving towards more digitised ways of working that help provide more data, the data itself remains siloed, unstructured and of low quality, making it’s suitability for deploying AI challenging. We then face the fact that projects are typically multi-month (if not year) long endeavours. As a result even the most prestigious organisations may only have records of, at most, a couple of thousand projects meaning the size of our potential datasets is often too limited to build robust predictions on.
But the biggest challenge with project data is we don’t have the counterfactuals nor a single metric to optimise one. Projects have a range of outcomes and most, if not all, projects have some areas that were very successful, some that were less so, and some areas that could have been much improved. But which are which, and what data and decisions are related to some subset of outcomes versus another? Today we can’t tell. And without this foundation we are struggling at the first gate.
But it isn’t just challenges with data we have to contend with. Most AI approaches today rely on two not very often talked about assumptions that don’t apply within a complex project setting:
- Ergodicity
- Static Distributions
Ergodicity
The first assumption most AI approaches take is that the underlying process it is trying to predict is ergodic. Er, ergo what? Ergodicity is a statistical term that in essence means that your sample of data is representative of the underlying process it was taken from.
More precisely ergodicity highlights the difference between the statistics across a group versus the statistics for an individual over time. Ergodic processes are ones in which taking the average result for an individual over time is the same as taking the average result over a group. Whereas non-ergodic processes are ones in which different individuals can have very different outcomes. It’s the difference between throwing dice (an ergodic process) and playing Russian roulette (a non-ergodic process). In throwing dice, I can take the statistics of one person throwing dice and robustly apply it to anyone else who throws the dice (assuming the dice are fair of course).
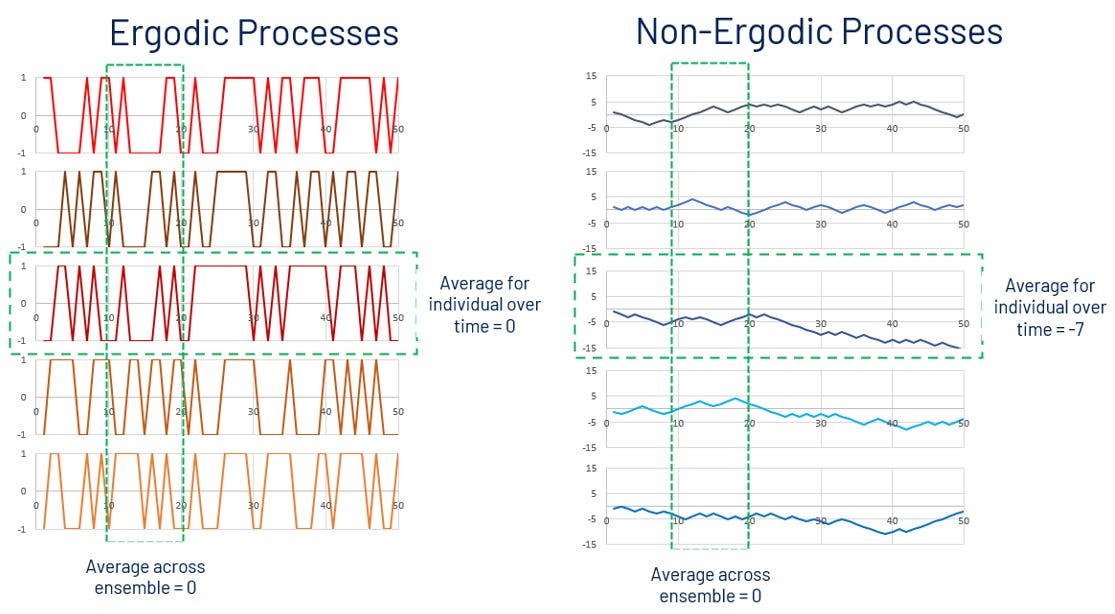
The challenges is that projects are more like playing Russian roulette than throwing dice. Projects are not just complicated they are complex. There are path dependencies, boundary conditions, and emergent processes that means projects are far from ergodic.
Or in simpler terms, you can never run the same project twice and get exactly the same result!
Adaptation
The second assumption most AI approaches take is that the underlying distribution is static. To understand this better consider a spam detection algorithm. You train the algorithm on a set of historical data where the emails are labelled as spam and not spam. With enough representative data this model will typically be very good at correctly classifying messages that are spam and those that are not.
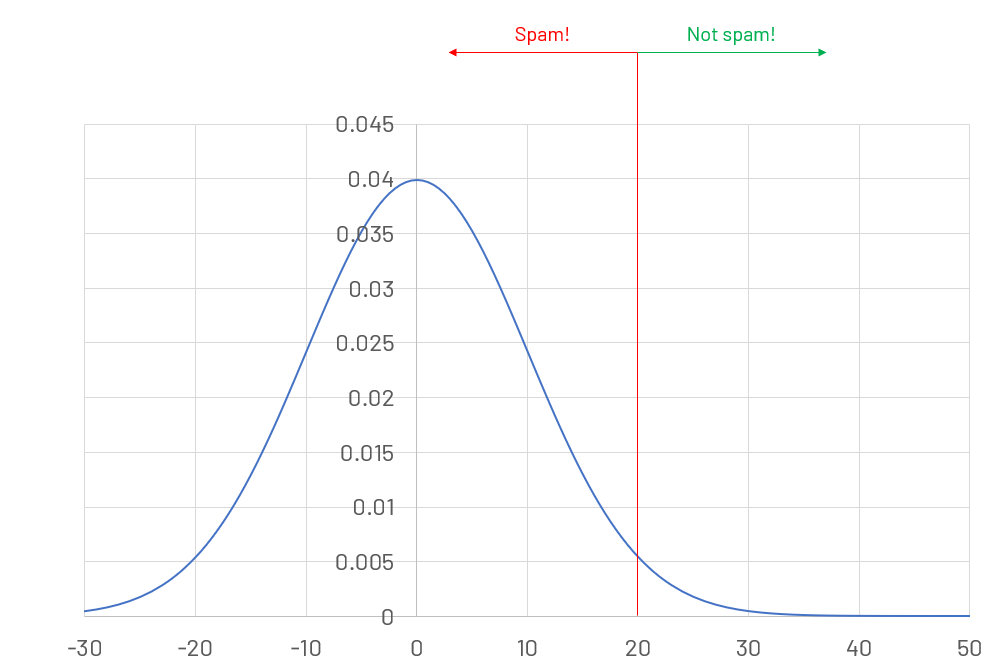
However, the world is not a static place. And our spam writers seeing that a high rate of their messages are getting caught by our algorithmic filter may start altering how they write their messages until they can bypass our filter once again. The real world distribution has moved away from the original training distribution and the AI model loses efficacy over time.
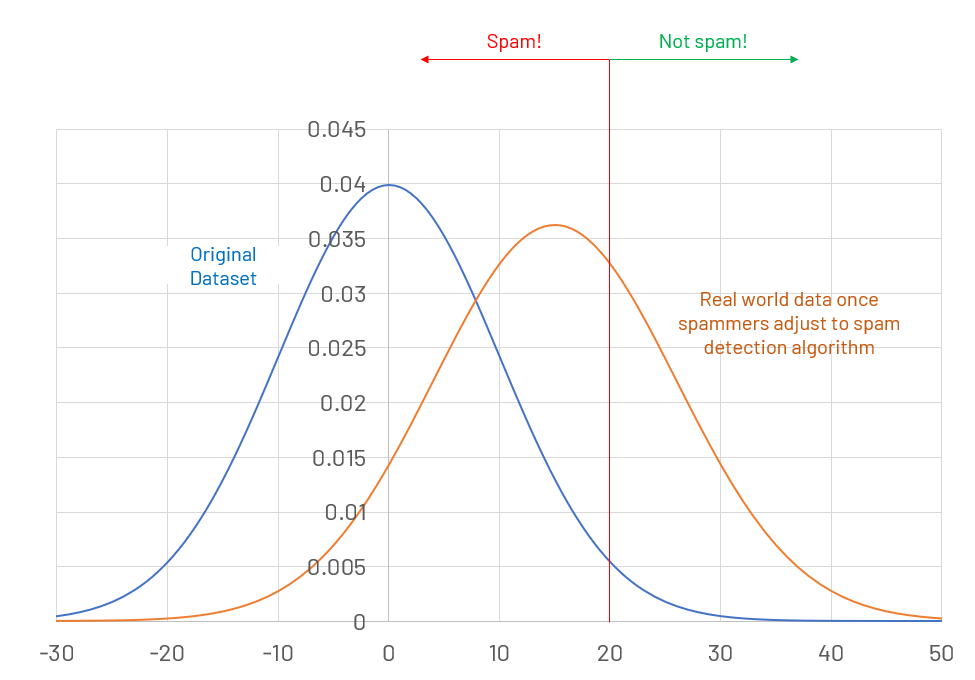
Likewise, engineering projects are adaptive processes. This means that we can expect changes as the project progresses and the project scope, budget, quality and resources may be altered as a result of that change.
Additionally, whilst projects don’t necessarily have quite the adversarial nature of spam writers and spam detectors it is certainly the case that projects are highly fragmented and different stakeholders will behave in different, and potentially unexpected, ways as the project progresses.
So the conditions, constraints and resources of our project will change over time as the work progresses. The challenge for AI is that these changes represent a shift in the underlying distribution of data. Without frequent retraining our models will lose relevancy over time.
Real World Problems
For all their impressiveness, algorithms have no real understanding of the world around them. They are leveraging statistics and huge amounts of data to make predictions. The responses of ChatGPT are at times jaw dropping but are in reality just the most likely output from a mathematical model of the problem space. At best, AI answers are probably approximately right. This means ChatGPT can hold realistic conversations with you but struggles to do basic math.
This is perfectly acceptable when the algorithm is being used to provide recommendations for your Thursday night TV watching or even for getting it to provide boilerplate code for a seasoned developer to adjust and optimise. However, it is a very different situation when we are expecting the algorithm to provide input to cost and schedule decisions and especially so when its output could have an impact on HSE.
Even the best of these algorithms make logical errors and these models can even “hallucinate”. It will provide a wrong answer as confidently as a right one and surround the wrong answer with what at first glance seems like reasonable arguments that on closer inspection bear no relation to the real world.
To quote Gary Marcus
“The reality is that large language models like GPT-3 and Galactica are like bulls in a china shop, powerful but reckless. And they are likely to vastly increase the challenge of misinformation”
Use these algorithms with caution!
Adoption
Even if we are able to overcome the first four challenges a fifth remains as highlighted in a recent McKinsey report. Whilst many organisations recognise the benefits of AI most are still struggling with challenges related to adoption.
From requirements, to digitalisation, to not having the skillsets, AI is proving tough to implement and scale. One challenge within a project environment is that there are too many potential use cases. However, just because you could do something doesn’t mean you should, or that it will prove technically (or financially!) feasible. Given limited time and resources what are the few use cases that you should focus your efforts on?
Another challenge of adoption is cost. Although it is hard to find an exact figure it is likely that training GPT3 cost in the order of $5M. And that was just to train it. To then get it to summarise, generate, or search text also costs additional computational time which doesn’t come cheap.
So where now?
So is that it then? People working on projects can rest assured that their jobs are secure knowing the limits of AI in projects. Well, no, not exactly. Whilst AI has some big limitations, AI has become incredibly powerful, and the progress I have witnessed in the past few years has been astounding.
Applying AI where it can work well can result in massive improvements in productivity. Large projects can easily generate over a billion words of text in project documentation. But, GPT3 could generate all of that text for just $27,000. Peanuts in comparison to how much projects are currently spending on generating, checking and managing their documentation. The challenge of course, is making sure that the AI generated work is relevant and compliant and delivers values to the customer.
But it is early days. My guess is that the hype over ChatGPT will die down a little over the next few months as people see its limitations in real world applications. However, over the next couple of years as people figure out how to collaborate and work effectively with, and alongside, these AI agents the way we work will be transformed. And I am sure projects ten years from now will be executed in radically different ways than they are today.
I am excited to be exploring how.
Notes:
- Throughout this article I have referred to Artificial Intelligence but I am strictly only talking about Machine Learning, one of the branches of AI.
- Some other content on chatGPT I’d recommend exploring:
- And this is a great article for better understanding the concept of Ergodicity and it’s wider implications: A Simple Explanation of Ergodic vs. Non-Ergodic
- OpenAI GPT-3: Everything You Need to Know
- GPT-4 Will Have 100 Trillion Parameters — 500x the Size of GPT-3
- We could run out of data to train ai language programs
- Cynefin framework
- Testing ChatGPT in Mathematics — Can ChatGPT do maths?
- Why Meta Took Down its ‘Hallucinating’ AI Model Galactica?
- Gary Marcus
- Adoption of AI advances, but foundational barriers remain
- OpenAI’s GPT-3 Language Model: A Technical Overview
- Pricing (openai.com)